


Hi all!
Before we jump in, two things:
I’m hosting a small event tomorrow (29th) with an RL expert and former head of ML at Twitter/X - come along if in Sydney! Details here, spots limited.
I have a new job! I share more about the change here.
Now, read on to go down an AGI rabbit hole.
What is all the madness about?
Honestly, my head is spinning right now. If you don’t follow AI as closely as I do, it’s crazy out there.
But we need to start from somewhere, so let’s pick up where we left off.
In my last edition of this blog, I shared that:
The returns to scale that underpinned basically all of the progress and investment into LLMs to date were possibly asymptoting, or no longer scaling in line with the fabled scaling laws (I’d say my confidence that this is true currently sits at ~30%).
Even if model pre-training wasn’t scaling as well anymore, there seemed to be great confidence from those within or close to the major labs that reinforcement learning (RL) was driving a new wave of progress (confidence in this has lifted to ~70%).
As a consequence of lower returns from scaling pre-training, we might see less investor confidence in backing big companies and less general market enthusiasm/hype.
Since I shared the above hypotheses I’ve spent 5 weeks in SF and, of course, we have seen the DeepSeek release that has since catalysed a "tech wipeout".
We’ve now moved from early rumours that RL experimentation was delivering strong outcomes within the major labs to all-out Freak Out Mode about what DeepSeek’s RL performance means for AI.
A researcher friend of mine said to me today:
“I called my dad, I rarely call him. It’s clear we are there. Basically any job in the service industry that is orthogonal to LLMs will suffer greatly. Jobs in LLM utilization/optimization/development will grow.”
Amusingly another researcher friend also called their dad after reading the DeepSeek papers and told them to prepare for a lot of change.
The thing that has researchers freaked out is the idea that we’re closer than we’ve ever been to the point at which AI can improve upon itself continuously, compounding on its own capabilities effortlessly and without end.
People have long speculated about this moment - it was coined the “singularity” in 1993. Here’s an explanation of the term from Claude:
The technological singularity refers to a hypothetical future point when artificial intelligence surpasses human intelligence and begins to enter a runaway cycle of self-improvement, leading to changes so rapid and profound that we cannot meaningfully predict what would happen afterward.
Naturally this has me like:

And it makes this tweet by Sam Altman feel more ominous:
This may sound like further hype and that’s something I wanted to understand more while I was in SF.
Were these improvements from RL real? Would they scale? Or was it the labs (OpenAI etc) talking themselves up so that they could raise more money? Were the researchers I speak to just drinking too much Bay Area Koolaid?
Both fortunately and unfortunately it seems that the excitement is founded on something real.
It’s fortunate because of the remarkable amount of good that could come from a singularity-induced Cambrian Explosion of scientific advancement.
It’s unfortunate because we are woefully unprepared and I’m quite worried about a period of joblessness and social upheaval.
Why has this model release suggested that we are nearing this point?
I’m not going to explain it better than Claude, so here’s an explainer from AI itself:
Think of teaching a child to solve math problems. Traditionally, we'd show them lots of example problems with solutions (this is like supervised learning), then have them practice while giving feedback (this is like traditional RLHF).
What DeepSeek did differently is more like giving a student a calculator and a way to check if their answers are correct, then letting them figure out the best methods on their own. Here's what made it work:
Clear Success Criteria:
They gave the AI simple ways to know if it got the right answer (like checking if a math solution is correct)
No human needed to say "good job" or "try again" - the AI could verify itself
Freedom to Explore:
Instead of being taught specific ways to solve problems, the AI was free to try different approaches
As long as it got to the right answer, it didn't matter how it got there
This led to the AI discovering novel problem-solving strategies
Iterative Improvement:
When the AI found methods that worked well, it naturally started using them more often
The paper shows this actually led to the AI developing better reasoning strategies than human-taught methods
Previous AI improvements heavily relied on human input - either through massive training datasets or direct human feedback. What makes DeepSeek's approach significant is that they showed an AI system can improve itself through self-verification and rule-based rewards, discovering novel problem-solving strategies without step-by-step human guidance.
While the system still operates within human-designed parameters and reward structures, it demonstrates that AI can meaningfully enhance its capabilities through self-guided exploration rather than requiring direct human teaching. This is a step toward recursive self-improvement because it begins to remove humans as a bottleneck in AI advancement.
It’s worth noting that there are still many problems that require human guidance, especially if success is not something that’s easy to “programmatically verify”. AKA: is there a way that the model can easily check its answers? Or do you need a human to tell it if it’s correct because there’s not a clear, obvious answer?
And why did this lead to a market drop?
DeepSeek has suggested that they trained their V3 model for around $5.5m USD, an astonishingly low amount given OpenAI is rumoured to be burning billions per year.
Though, in the words of a friend of mine who’s closer to the details on building these models:
The quoted training costs are misleading at best, because many runs occur before a final model release, and are more likely a complete fabrication. In any case, DeepSeek's cost savings are the product of architectural tweaks; they do little to address the sheer computational intensity of reinforcement learning. It will soon become obvious that scaling RL is the most important thing in AI, and that by implication, capital and compute remain key moats.
They’re also offering the model for incredibly low prices both in an absolute sense and in the context of how intelligent it is. It’s also (mostly) open source, making it clear to everyone what techniques they used to get there.
From Artificial Analysis:
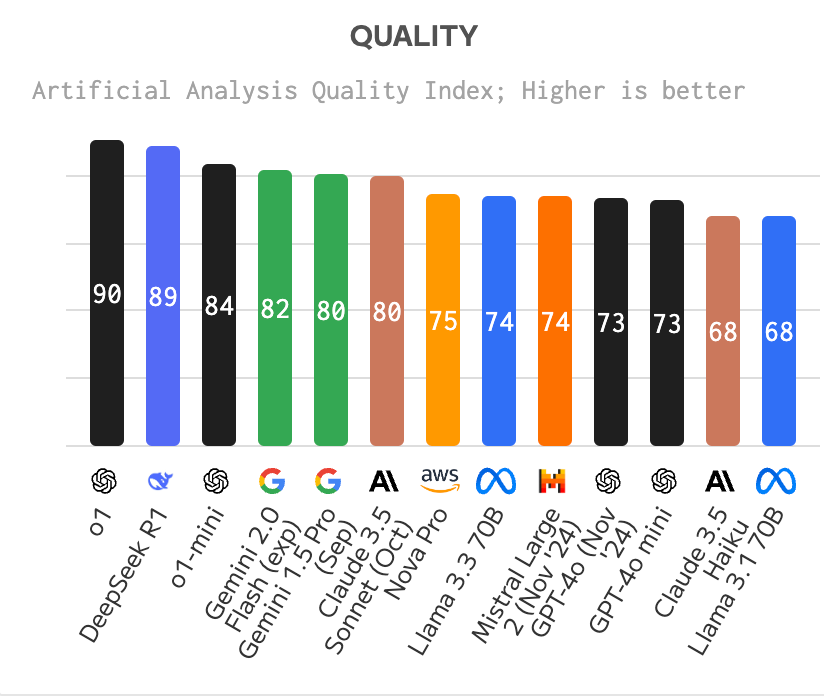

This has led to concerns around 1) whether there will be a massive oversupply in chips (namely GPUs) if it’s not required to spend billions on training and 2) whether players like OpenAI and Anthropic have any moat.
I will write more about this in future but in the meantime, it’s worth reading this post by one of the founding team members of OpenAI, Andrej Karpathy:
I don't have too too much to add on top of this earlier post on V3 and I think it applies to R1 too (which is the more recent, thinking equivalent).
I will say that Deep Learning has a legendary ravenous appetite for compute, like no other algorithm that has ever been developed in AI. You may not always be utilizing it fully but I would never bet against compute as the upper bound for achievable intelligence in the long run. Not just for an individual final training run, but also for the entire innovation / experimentation engine that silently underlies all the algorithmic innovations.
Data has historically been seen as a separate category from compute, but even data is downstream of compute to a large extent - you can spend compute to create data. Tons of it. You've heard this called synthetic data generation, but less obviously, there is a very deep connection (equivalence even) between "synthetic data generation" and "reinforcement learning". In the trial-and-error learning process in RL, the "trial" is model generating (synthetic) data, which it then learns from based on the "error" (/reward). Conversely, when you generate synthetic data and then rank or filter it in any way, your filter is straight up equivalent to a 0-1 advantage function - congrats you're doing crappy RL.
Last thought. Not sure if this is obvious. There are two major types of learning, in both children and in deep learning. There is 1) imitation learning (watch and repeat, i.e. pretraining, supervised finetuning), and 2) trial-and-error learning (reinforcement learning). My favorite simple example is AlphaGo - 1) is learning by imitating expert players, 2) is reinforcement learning to win the game. Almost every single shocking result of deep learning, and the source of all *magic* is always 2. 2 is significantly significantly more powerful. 2 is what surprises you. 2 is when the paddle learns to hit the ball behind the blocks in Breakout. 2 is when AlphaGo beats even Lee Sedol. And 2 is the "aha moment" when the DeepSeek (or o1 etc.) discovers that it works well to re-evaluate your assumptions, backtrack, try something else, etc. It's the solving strategies you see this model use in its chain of thought. It's how it goes back and forth thinking to itself. These thoughts are *emergent* (!!!) and this is actually seriously incredible, impressive and new (as in publicly available and documented etc.). The model could never learn this with 1 (by imitation), because the cognition of the model and the cognition of the human labeler is different. The human would never know to correctly annotate these kinds of solving strategies and what they should even look like. They have to be discovered during reinforcement learning as empirically and statistically useful towards a final outcome.
If you read this far, thanks! I’m going to leave it here for now but safe to say we are just at the beginning.
Thanks,
Casey
Good writeup. I am surprised the anonymous researchers mentioned seem to update more on the DS results, rather than o3 benchmarks? I guess we will just go even faster but I found that event 'spookier'.