

What if vibe coding spells the end of the software industry?
Software has been eating the world; AI is on track to eat software and much more

Hi all!
Included in this edition:
What vibe coding foreshadows for the software industry
A quick tidbit on AI costs
My content diet of late
What if vibe coding spells the end of the software industry?
“Vibe coding” is a phrase people are loving on X/Twitter right now. I’d describe it as letting AI take the wheel while programming. In the words of Andrej Karpathy:
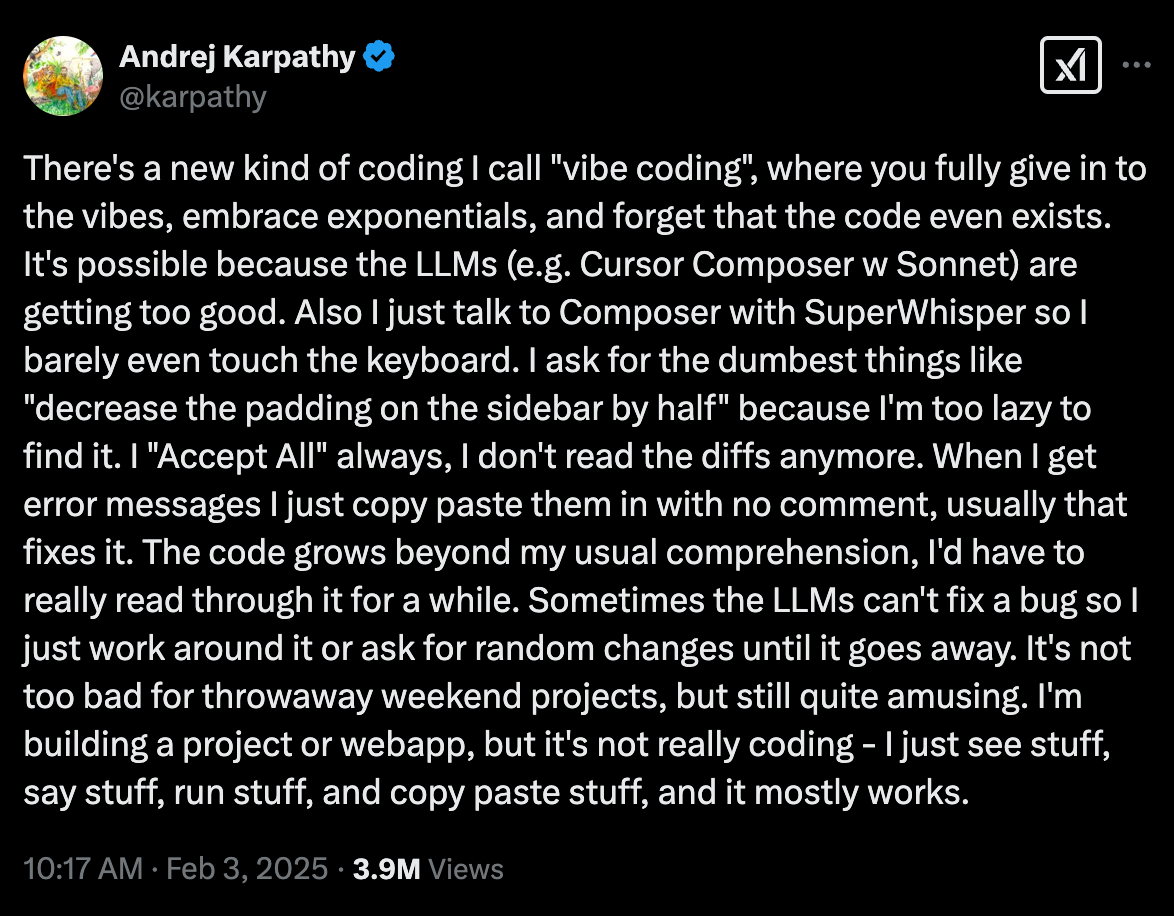
I’ve been trying the various code generation tools for a while now but it feels like they have really hit their stride now.
In particular, using Windsurf and Replit’s new mobile app recently shook my views on software.
I’d describe using Windsurf in particular as a magical experience. To see AI effectively build whatever I want using just natural language instructions and some app screenshots is truly incredible.
This experience made me wonder: how much harder will selling software be when everyone can make their own bespoke version in ten minutes? What happens to the software market?
Large enterprises love bespoke versions of software. It’s a common trap for startups: to get caught in shipping product for one big customer’s asks instead of what’s aligned with their true vision.
And smaller companies don’t want to pay large subscription fees for third-party software and are more likely to “make do” with what they can build themselves.
This really complicates the “build or buy” equation that anyone building software has had to navigate when selling to their target customer.
It also makes clearer a path to economic domination by the large model providers.
Something the most bullish AGI folks I talk to have been saying for a while is that problem-specific software doesn’t need to exist in a world where foundation models can do so much.
Let’s call this idea universal software for short given AGI is such a loaded term.
I could dedicate an even longer blog post to this idea but in short: in a world where custom software (including the backend and a snazzy interface) can be built in such a short amount of time by a model, who’s to say you won’t be able to do that directly from ChatGPT or Anthropic’s Claude for every task you need automated or want an interface for?
After all, it’s Anthropic and OpenAI’s models (Sonnet 3.5 and o1 respectively) that are currently powering the most popular code generation tools.
It seems increasingly feasible to me that ChatGPT or Claude could graduate from “a better version of Google” to something that replaces all of the software in your life. They could then absorb all of the economic value currently distributed across the software industry.
This is, according to people I’ve spoken to at some of the top AI labs, part of the explicit goal. Why wouldn’t it be? It’s a >$1.6T opportunity based on today’s software spend (which doesn’t include value capture expansion as AI takes on more problems!).
This might sound like a hyperbolic concept but when you try Windsurf or Replit I think you’ll see how real a possibility this has become.
Of course, it’s clear that we’re not at 100% yet. Getting to 90% right now is pretty magical, but getting to 100% can be frustrating. Companies like Replit are solving this by connecting projects to software engineers who can do the last-mile work to polish and productionise Replit apps.
The recent breakthroughs in reinforcement learning seems to increase this likelihood even further.
I need to test this with people more knowledgeable than I but if reinforcement learning does enable the next wave of foundation model improvements as suspected, I wonder if it accelerates the path to universal software in more ways than one.
There’s a direct benefit of improved reasoning capabilities, and
An indirect benefit of having a method for training models on specific workflows
I wrote in Ruminations #20:
I personally believe initiatives around computer interface tools, like OpenAI’s upcoming “Operator” are part of strategies to generate more data through reinforcement learning.
If you’re able to collect data on what a complete and effective workflow looks like for a given job or task (like submitting tax returns, lodging an expense, balancing accounts, interfacing with a CRM, working as an accounts payable clerk, developing a building design etc etc) using captured behaviour via screen scraping or something like Operator, you could feasibly train a model using RL to do the same.
Historically, the granular steps in these workflows haven’t been on the open internet and so it’s not been accessible information for model pre-training.
Subsequently, models don’t yet have a good idea of how to break down high level task instructions for more domain-specific workflows. For example: “you’re an architect, design a building” or “you’re an accountant, reconcile this customer’s accounts using our systems”.
Using RL and tools like OpenAI’s Operator or Anthropic’s Computer Use API the big model players may be able to get more of that context. In the meantime, I understand that these players are using partners like Scale AI to hire specialists (like doctors or developers for example) to act as teachers to their models, working with the models to help coach them on their way to breaking down and solving complex workflows.
All of this throws into question the current VC strategy around investing in very domain-specific software. This approach was underpinned by the belief that a large horizontal player would struggle to compete with a vertically focussed player (as has been true of software historically).
This may still be true, but the ground is getting shakier as AI gets stronger.
Quick tidbit on model costs
A lot of people who are further from the details of AI research seem concerned about AI costs. This writing by Sam Altman shares some interesting context on costs.

My information diet
Here are some of the podcasts I’ve listened to over the last couple of weeks and recommend. The sooner we get Neuralink so that I can absorb all of these updates in my sleep, the better because it’s a lot!
Gradient Dissent: R1, OpenAI’s o3, and the ARC-AGI Benchmark: Insights from Mike Knoop
Mike Knoop seems like a legend, I thought he provided one of the best explanations I’ve heard on R1.
Latent Space: The Agent Reasoning Interface with OpenAI’s Karina Nguyen
It was really interesting hearing Karina’s reflections on the early days of Anthropic and her work at OpenAI, including her pivot from product design to research which I love to see.
Acquired: TSMC Founder Morris Chang
This was a really enjoyable listen. I was surprised by how passionately Chang is about how people management should be approached (doesn’t believe in layoffs, prefers not to fire anyone!). He is clearly still annoyed at the CEO he tried to hire to fill his shoes earlier in the business’ history.
20VC: Jonathan Ross (founder of Groq)
The commentary I’ve heard from people in the semiconductor space and from Google paint Jonathan as a polarising character but I really enjoyed this episode. Not sure I agreed with everything he had to say but a good listen.
Lex Fridman Podcast: DeepSeek, China, OpenAI, NVIDIA, xAI, TSMC, Stargate and AI Megaclusters
People who are close to me know I love geopolitics and so I really get around any commentary that weaves that together with AI and the fun dynamics of its supply chain. I spend more time consuming geopolitics content than AI content, which should concern anyone sane given how much AI content I consume.
No Priors: DeepSeek, Deep Research, and 2025 predictions
I haven’t listened to this one yet, but Elad and Sarah are great to listen to if you want to get a sense of what’s going on.
Andrej Kaparthy: Deep Dive into LLMs like ChatGPT
Also on my to-consume list is this monster three-hour video from Andrej Karpathy on understanding LLMs.
Thanks for making it this far! Feedback always welcome.
Enjoy your week.
Disclaimer: the views shared in this blog are proudly my own and don’t represent any organisation associated with me.
Why is the operator/visual workflow data important? The DeepSeek R1 paper in my mind argued that R1-Zero's impact, self reinforcement on evaluatable objectives, was more than the human chain SFT on top. Models with richer reasoning chain data are still better, but why then operator. My intuition is that the data on Airbnb's feedback form page is low signal, especially when you lack the primitives on how its built. Am I missing something?